
Agent 时代,需要一台能折叠的「移动工作台」|AIDONE 5.0 全记录
Agent 时代,需要一台能折叠的「移动工作台」|AIDONE 5.0 全记录前阵子有张梗图,在 AI Agent 圈子里火了:
来自主题: AI资讯
10598 点击 2026-06-12 10:02
 搜索
搜索
前阵子有张梗图,在 AI Agent 圈子里火了:
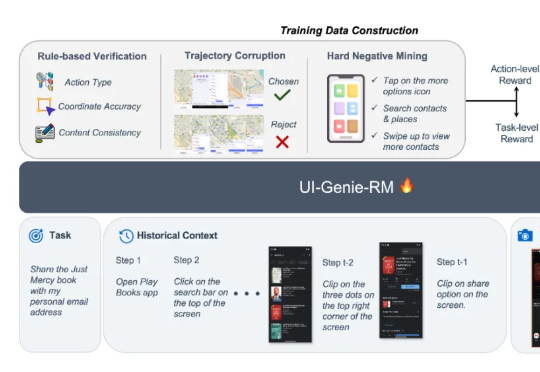
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
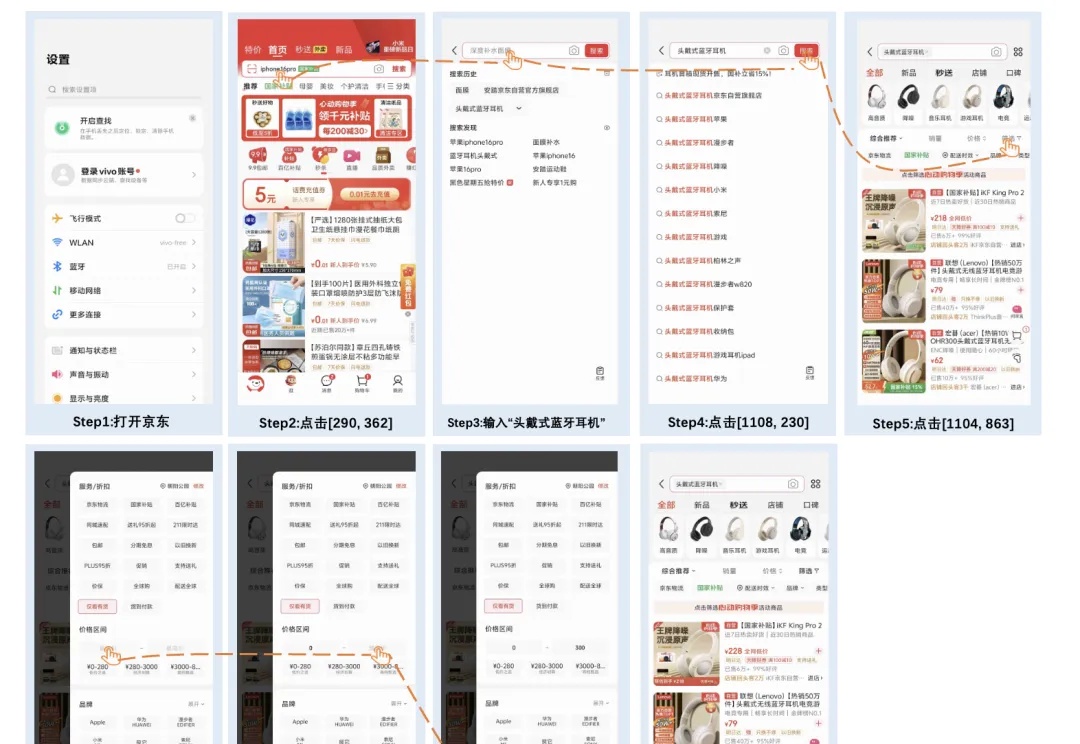
机器之心报道 编辑:泽南 真正实用化的生成式 AI,应该是这个样子 —— 作为助手可以帮你代打电话,根据你的选项进行应答,还能引导对方转人工: 功能覆盖多个场景,连接大量第三方应用,实现多智能体的一键
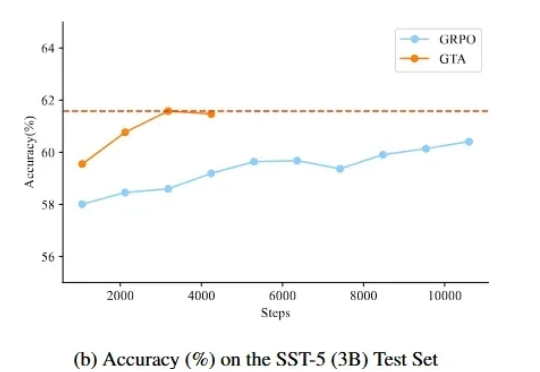
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
vivo AI Lab发布AI多模态新模型了,专门面向端侧设计,紧凑高效~
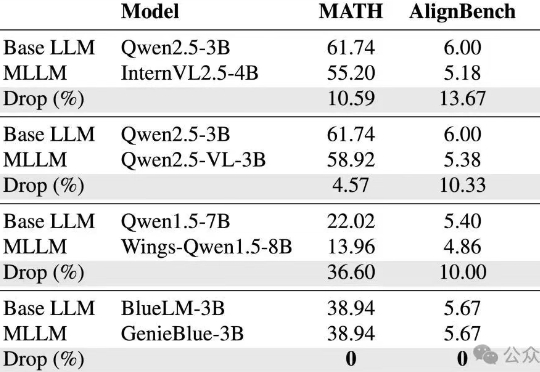
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。
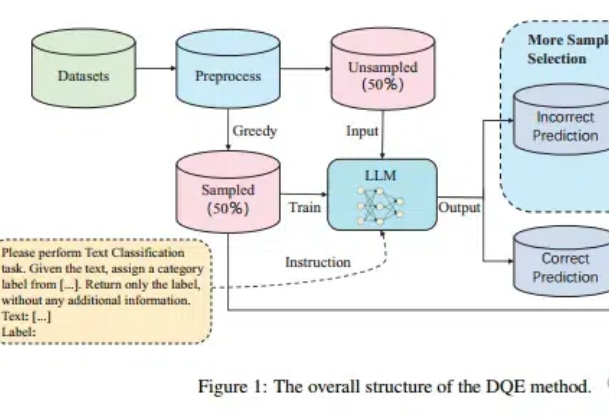
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。

BlueLM-V-3B 是一款由 vivo AI 研究院与香港中文大学联合研发的端侧多模态模型。该模型现已完成对天玑 9300 和 9400 芯片的初步适配,未来将逐步推出手机端应用,为用户带来更智能、更便捷的体验。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

vivo副总裁、OS产品副总裁、vivo AI全球研究院院长周围,在MEET智能未来大会上表示:大模型目前最能完成体验闭环和商业闭环的场景,就是落地在手机上,打造智能体。